Vom Rohdatenbestand zum Unternehmenswert: Phasen der systematischen Wertschöpfung aus Daten
Der Data Value Lifecycle ist ein strategisches Modell zur gezielten Realisierung von Datenwert. Dieses Whitepaper zeigt die zentralen Phasen – von Business Alignment bis Monetarisierung – und unterstützt dabei, datenbasierte Initiativen messbar zu steuern und das Datenmanagement nachhaltig zu verbessern.


Die Wertschöpfung aus Daten ist kein einmaliger Akt, sondern ein kontinuierlicher Prozess. Der sogenannte Data Value Lifecycle beschreibt die Etappen, die Unternehmen durchlaufen müssen, um aus Rohdaten verwertbare Erkenntnisse und monetarisierbare Ergebnisse zu generieren. Für Unternehmen bietet dieser Lifecycle eine praxisnahe Orientierung, wie Daten gezielt aufgebaut, bewertet, genutzt und in Wertüberführt werden können.
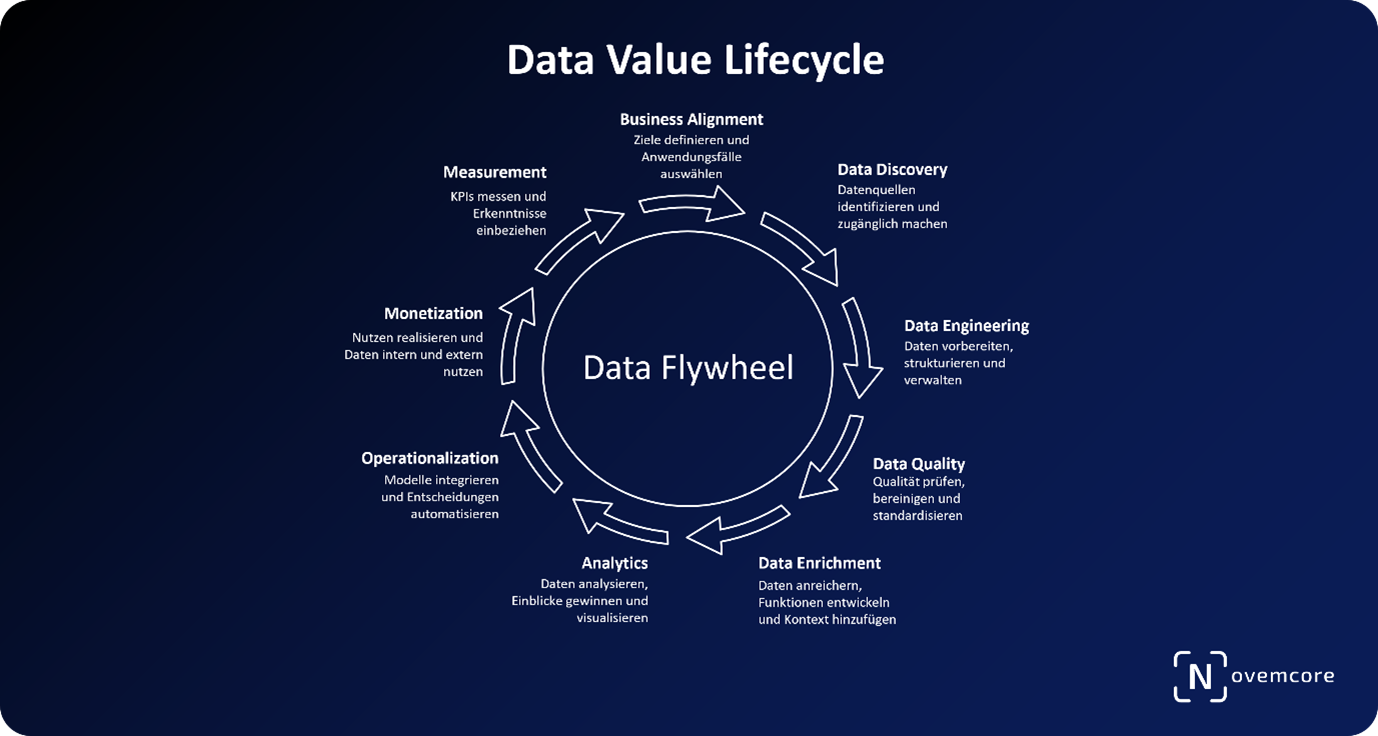
Phase 0: Business Alignment & Use-Case Definition
Am Anfang jeder datenbasierten Initiative steht die geschäftliche Zieldefinition. Dabei werden strategisch relevante Fragestellungen identifiziert, Prioritäten festgelegt und potenzielle Use Cases formuliert. Der Fokus liegt auch auf der Messbarkeit: Welche KPIs sollen beeinflusst werden? Wie lässt sich der ROI quantifizieren? Ein strukturierter Value-Vision-Workshopschafft Klarheit über Erwartungen, Risiken und Machbarkeit.
Phase 1: Data Discovery & Acquisition
In dieser Phase werden interne und externe Datenquellen identifiziert, erschlossen und technisch zugänglich gemacht. Dabei geht es nicht nur um Datenmenge, sondern insbesondere um Relevanz, Granularität und Integrationsfähigkeit. Der Aufbau eines zentralen, zugänglichen Datenpools legt die Grundlage für skalierbare Anwendungen.
Phase 2: Data Engineering & Governance
Sobald Datenquellen identifiziert sind, folgt die technische Aufbereitung. Hierzu zählen Datenmodellierung, Speicherung, Zugriffskontrolle und Einhaltung regulatorischer Vorgaben. Ziel ist eine robuste, sichere und skalierbare Datenarchitektur. Governance-Funktionen wie Rollenmodelle, Datenverantwortlichkeiten und Compliance-Richtlinien sichern die nachhaltige Nutzung.
Phase 3: Data Quality Management
Die Qualität der Daten entscheidet über den Wert. Nur konsistente, vollständige und aktuelle Daten erlauben valide Analysen und verlässliche Entscheidungen. In dieser Phase kommen Methoden wie Data Profiling, Cleansing, Matching und Harmonisierung zum Einsatz. Die Verankerung von Data Quality als kontinuierlicher Prozess ist Voraussetzung für alle nachgelagerten Schritte.
Phase 4: Data Enrichment & Feature Engineering
Rohdaten entfalten erst dann ihren vollen Wert, wenn sie angereichert und in sinnvolle Strukturen überführt werden. Dabei werden externe Quellen, Kontextinformationen oder berechnete Variablen hinzugezogen. Mittels Feature Stores (z. B. Feast, Databricks FS) lassen sich daraus wiederverwendbare Komponenten für Machine-Learning-Modelle entwickeln. Dieser Schritt ist entscheidend, um aus unstrukturierten oder domänenspezifischen Daten geschäftsrelevante Merkmale zu extrahieren.
Phase 5: Analytics & Insight Generation
In dieser Phase werden die angereicherten Daten genutzt, um deskriptive, prädiktive oder präskriptive Analysen durchzuführen. Dabei kommen sowohl klassische BI-Visualisierungs-Tools (Power BI, Tableau) als auch Machine-Learning-Umgebungen (z. B. in Python, R, AutoML) zum Einsatz. Ziel ist es, Entscheidungsgrundlagen zu schaffen, Hypothesen zu testen und operative Prozesse datenbasiert zu steuern. Insights müssen verständlich kommuniziert und visualisiert werden – etwa in interaktiven Dashboards oder automatisierten Reports.
Phase 6: Operationalization & Decisioning
Erkenntnisse allein reichen nicht – sie müssen produktiv genutzt werden. Daher werden analytische Modelle und Entscheidungsregeln in bestehende Systeme integriert – etwa über APIs, RPA-Prozesse oder in ERP-/CRM-Systeme. Hier entscheidet sich, ob der Business Impact tatsächlich realisiert wird. Regelmäßige Überwachung (Monitoring, A/B-Tests, Modell-Drift-Erkennung) ist notwendig, um die Wirksamkeit in der Praxis sicherzustellen.
Phase 7: Value Realization & Monetization
Hier tritt der ökonomische Nutzen zutage: durch geringere Kosten, höhere Umsätze oder direkte Datenvermarktung. Je nach Geschäftsmodell stehen unterschiedliche Monetarisierungsformen im Vordergrund – von interner Effizienz über Produktivitätssteigerung bis hin zu Insights-as-a-Service. Preismodelle, Lizenzlogiken und Marktkanäle (z. B. Snowflake Marketplace, Dawex) flankieren die externe Kommerzialisierung.
Phase 8: Measurement & Continuous Improvement
Datenstrategien enden nicht mit der ersten Monetarisierung. Ein Data Value Cockpit visualisiert die Fortschritte in KPIs wie Data Leverage Index, Return on Data Assets oder Datenqualitätsmetriken. Gelerntes wird systematisch zurückgeführt, neue Use Cases priorisiert und bestehende Modelle angepasst. Der Lifecycle wird zum „Data Flywheel“: Jeder Zyklus erhöht die Reife, den Nutzen und das monetäre Potenzial der Unternehmensdaten.
Häufige Fragen (FAQ):
1. Was versteht man unter dem Data Value Lifecycle?
Der Data Value Lifecycle ist ein strategisches Modell zur Datenwertschöpfung und beschreibt, wie Unternehmen aus Rohdaten wirtschaftlichen Nutzen generieren– von Datenaufbau bis zur Monetarisierung.
2. Wie entsteht wirtschaftlicher Mehrwert aus Daten?
Wirtschaftlicher Mehrwert entsteht durch die gezielte Nutzung von Daten zur Prozessoptimierung, besseren Entscheidungen und neuen Geschäftsmodellen, inklusive Datenmonetarisierung.
3. Welche Phasen umfasst der Data Value Lifecycle?
Der Lifecycle reicht von Business Alignment, Datenerfassung, Datenqualität, Analyse und Operationalisierung bis zu Monetarisierung und kontinuierlicher Verbesserung.
4. Warum ist Datenqualität entscheidend für den Datenwert?
Ohne konsistente, vollständige und aktuelle Daten sind Analysen unzuverlässig – nur hochwertige Daten ermöglichen valide Insights und reale Wertschöpfung.
5. Wie lassen sich Daten systematisch monetarisieren?
Daten können intern zur Effizienzsteigerung genutzt oder extern vermarktet werden – z. B. über Lizenzmodelle, Datenmarktplätze oder Insights-as-a-Service.
6. Was ist eine erfolgreiche Datenstrategie?
Eine erfolgreiche Datenstrategie verbindet Geschäftsziele mit Technologie, stellt Datenqualität sicher, definiert Governance und realisiert datenbasierte Wertschöpfung messbar.
7. Wie misst man den Erfolg datengetriebener Initiativen?
Kennzahlen wie Return on Data Assets, Data Leverage Index oder Umsatzbeitrag pro Use Case helfen, den wirtschaftlichen Nutzen datenbasierter Maßnahmen zu bewerten.
Vom Rohdatenbestand zum Unternehmenswert: Phasen der systematischen Wertschöpfung aus Daten
Der Data Value Lifecycle ist ein strategisches Modell zur gezielten Realisierung von Datenwert. Dieses Whitepaper zeigt die zentralen Phasen – von Business Alignment bis Monetarisierung – und unterstützt dabei, datenbasierte Initiativen messbar zu steuern und das Datenmanagement nachhaltig zu verbessern.
Die Wertschöpfung aus Daten ist kein einmaliger Akt, sondern ein kontinuierlicher Prozess. Der sogenannte Data Value Lifecycle beschreibt die Etappen, die Unternehmen durchlaufen müssen, um aus Rohdaten verwertbare Erkenntnisse und monetarisierbare Ergebnisse zu generieren. Für Unternehmen bietet dieser Lifecycle eine praxisnahe Orientierung, wie Daten gezielt aufgebaut, bewertet, genutzt und in Wertüberführt werden können.
Phase 0: Business Alignment & Use-Case Definition
Am Anfang jeder datenbasierten Initiative steht die geschäftliche Zieldefinition. Dabei werden strategisch relevante Fragestellungen identifiziert, Prioritäten festgelegt und potenzielle Use Cases formuliert. Der Fokus liegt auch auf der Messbarkeit: Welche KPIs sollen beeinflusst werden? Wie lässt sich der ROI quantifizieren? Ein strukturierter Value-Vision-Workshopschafft Klarheit über Erwartungen, Risiken und Machbarkeit.
Phase 1: Data Discovery & Acquisition
In dieser Phase werden interne und externe Datenquellen identifiziert, erschlossen und technisch zugänglich gemacht. Dabei geht es nicht nur um Datenmenge, sondern insbesondere um Relevanz, Granularität und Integrationsfähigkeit. Der Aufbau eines zentralen, zugänglichen Datenpools legt die Grundlage für skalierbare Anwendungen.
Phase 2: Data Engineering & Governance
Sobald Datenquellen identifiziert sind, folgt die technische Aufbereitung. Hierzu zählen Datenmodellierung, Speicherung, Zugriffskontrolle und Einhaltung regulatorischer Vorgaben. Ziel ist eine robuste, sichere und skalierbare Datenarchitektur. Governance-Funktionen wie Rollenmodelle, Datenverantwortlichkeiten und Compliance-Richtlinien sichern die nachhaltige Nutzung.
Phase 3: Data Quality Management
Die Qualität der Daten entscheidet über den Wert. Nur konsistente, vollständige und aktuelle Daten erlauben valide Analysen und verlässliche Entscheidungen. In dieser Phase kommen Methoden wie Data Profiling, Cleansing, Matching und Harmonisierung zum Einsatz. Die Verankerung von Data Quality als kontinuierlicher Prozess ist Voraussetzung für alle nachgelagerten Schritte.
Phase 4: Data Enrichment & Feature Engineering
Rohdaten entfalten erst dann ihren vollen Wert, wenn sie angereichert und in sinnvolle Strukturen überführt werden. Dabei werden externe Quellen, Kontextinformationen oder berechnete Variablen hinzugezogen. Mittels Feature Stores (z. B. Feast, Databricks FS) lassen sich daraus wiederverwendbare Komponenten für Machine-Learning-Modelle entwickeln. Dieser Schritt ist entscheidend, um aus unstrukturierten oder domänenspezifischen Daten geschäftsrelevante Merkmale zu extrahieren.
Phase 5: Analytics & Insight Generation
In dieser Phase werden die angereicherten Daten genutzt, um deskriptive, prädiktive oder präskriptive Analysen durchzuführen. Dabei kommen sowohl klassische BI-Visualisierungs-Tools (Power BI, Tableau) als auch Machine-Learning-Umgebungen (z. B. in Python, R, AutoML) zum Einsatz. Ziel ist es, Entscheidungsgrundlagen zu schaffen, Hypothesen zu testen und operative Prozesse datenbasiert zu steuern. Insights müssen verständlich kommuniziert und visualisiert werden – etwa in interaktiven Dashboards oder automatisierten Reports.
Phase 6: Operationalization & Decisioning
Erkenntnisse allein reichen nicht – sie müssen produktiv genutzt werden. Daher werden analytische Modelle und Entscheidungsregeln in bestehende Systeme integriert – etwa über APIs, RPA-Prozesse oder in ERP-/CRM-Systeme. Hier entscheidet sich, ob der Business Impact tatsächlich realisiert wird. Regelmäßige Überwachung (Monitoring, A/B-Tests, Modell-Drift-Erkennung) ist notwendig, um die Wirksamkeit in der Praxis sicherzustellen.
Phase 7: Value Realization & Monetization
Hier tritt der ökonomische Nutzen zutage: durch geringere Kosten, höhere Umsätze oder direkte Datenvermarktung. Je nach Geschäftsmodell stehen unterschiedliche Monetarisierungsformen im Vordergrund – von interner Effizienz über Produktivitätssteigerung bis hin zu Insights-as-a-Service. Preismodelle, Lizenzlogiken und Marktkanäle (z. B. Snowflake Marketplace, Dawex) flankieren die externe Kommerzialisierung.
Phase 8: Measurement & Continuous Improvement
Datenstrategien enden nicht mit der ersten Monetarisierung. Ein Data Value Cockpit visualisiert die Fortschritte in KPIs wie Data Leverage Index, Return on Data Assets oder Datenqualitätsmetriken. Gelerntes wird systematisch zurückgeführt, neue Use Cases priorisiert und bestehende Modelle angepasst. Der Lifecycle wird zum „Data Flywheel“: Jeder Zyklus erhöht die Reife, den Nutzen und das monetäre Potenzial der Unternehmensdaten.
Häufige Fragen (FAQ):
1. Was versteht man unter dem Data Value Lifecycle?
Der Data Value Lifecycle ist ein strategisches Modell zur Datenwertschöpfung und beschreibt, wie Unternehmen aus Rohdaten wirtschaftlichen Nutzen generieren– von Datenaufbau bis zur Monetarisierung.
2. Wie entsteht wirtschaftlicher Mehrwert aus Daten?
Wirtschaftlicher Mehrwert entsteht durch die gezielte Nutzung von Daten zur Prozessoptimierung, besseren Entscheidungen und neuen Geschäftsmodellen, inklusive Datenmonetarisierung.
3. Welche Phasen umfasst der Data Value Lifecycle?
Der Lifecycle reicht von Business Alignment, Datenerfassung, Datenqualität, Analyse und Operationalisierung bis zu Monetarisierung und kontinuierlicher Verbesserung.
4. Warum ist Datenqualität entscheidend für den Datenwert?
Ohne konsistente, vollständige und aktuelle Daten sind Analysen unzuverlässig – nur hochwertige Daten ermöglichen valide Insights und reale Wertschöpfung.
5. Wie lassen sich Daten systematisch monetarisieren?
Daten können intern zur Effizienzsteigerung genutzt oder extern vermarktet werden – z. B. über Lizenzmodelle, Datenmarktplätze oder Insights-as-a-Service.
6. Was ist eine erfolgreiche Datenstrategie?
Eine erfolgreiche Datenstrategie verbindet Geschäftsziele mit Technologie, stellt Datenqualität sicher, definiert Governance und realisiert datenbasierte Wertschöpfung messbar.
7. Wie misst man den Erfolg datengetriebener Initiativen?
Kennzahlen wie Return on Data Assets, Data Leverage Index oder Umsatzbeitrag pro Use Case helfen, den wirtschaftlichen Nutzen datenbasierter Maßnahmen zu bewerten.